Linux 内核提供了不少有力的加锁原语能够用来使内核避免被自己绊倒. 但是, 如同我们已见到的, 一个加锁机制的设计和实现不是没有缺陷. 常常对于旗标和自旋锁没有选择; 它们可能是唯一的方法来正确地完成工作. 然而, 有些情况, 可以建立原子的存取而不用完整的加锁. 本节看一下做事情的其他方法.
有时, 你可以重新打造你的算法来完全避免加锁的需要. 许多读者/写者情况 -- 如果只有一个写者 -- 常常能够在这个方式下工作. 如果写者小心使数据结构的视图, 由读者所见的, 是一直一致的, 有可能创建一个不加锁的数据结构.
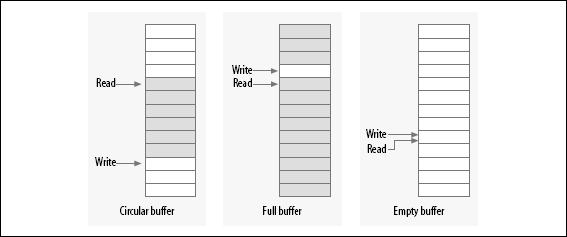
常常可以对无锁的生产者/消费者任务有用的数据结构是环形缓存. 这个算法包含一个生产者安放数据到一个数组的尾端, 而消费者从另一端移走数据. 当到达数组末端, 生产者绕回到开始. 因此一个环形缓存需要一个数组和 2 个索引值来跟踪下一个新值放到哪里, 以及哪个值在下一次应当从缓存中移走.
当小心地实现了, 一个环形缓存在没有多个生产者或消费者时不需要加锁. 生产者是唯一允许修改写索引和它所指向的数组位置的线程. 只要写者在更新写索引之前存储一个新值到缓存中, 读者将一直看到一个一致的视图. 读者, 轮换地, 是唯一存取读索引和它指向的值的线程. 加一点小心到确保 2 个指针不相互覆盖, 生产者和消费者可以并发存取缓存而没有竞争情况.
图环形缓冲展示了在几个填充状态的环形缓存. 这个缓存被定义成一个空情况由读写指针相同来指示, 而满情况发生在写指针紧跟在读指针后面的时候(小心解决绕回!). 当小心地编程, 这个缓存能够不必加锁地使用.
在设备驱动中环形缓存出现相当多. 网络适配器, 特别地, 常常使用环形缓存来与处理器交换数据(报文). 注意, 对于 2.6.10, 有一个通用的环形缓存实现在内核中可用; 如何使用它的信息看 <linux/kfifo.h>.
有时, 一个共享资源是一个简单的整数值. 假设你的驱动维护一个共享变量 n_op, 它告知有多少设备操作目前未完成. 正常地, 即便一个简单的操作例如:
n_op++;
可能需要加锁. 某些处理器可能以原子的方式进行那种递减, 但是你不能依赖它. 但是一个完整的加锁体制对于一个简单的整数值看来过分了. 对于这样的情况, 内核提供了一个原子整数类型称为 atomic_t, 定义在 <asm/atomic.h>.
一个 atomic_t 持有一个 int 值在所有支持的体系上. 但是, 因为这个类型在某些处理器上的工作方式, 整个整数范围可能不是都可用的; 因此, 你不应当指望一个 atomic_t 持有多于 24 位. 下面的操作为这个类型定义并且保证对于一个 SMP 计算机的所有处理器来说是原子的. 操作是非常快的, 因为它们在任何可能时编译成一条单个机器指令.
- void atomic_set(atomic_t *v, int i);
- atomic_t v = ATOMIC_INIT(0);
设置原子变量 v 为整数值 i. 你也可在编译时使用宏定义 ATOMIC_INIT 初始化原子值.
- int atomic_read(atomic_t *v);
返回 v 的当前值.
- void atomic_add(int i, atomic_t *v);
由 v 指向的原子变量加 i. 返回值是 void, 因为有一个额外的开销来返回新值, 并且大部分时间不需要知道它.
- void atomic_sub(int i, atomic_t *v);
从 *v 减去 i.
- void atomic_inc(atomic_t *v);
- void atomic_dec(atomic_t *v);
递增或递减一个原子变量.
- int atomic_inc_and_test(atomic_t *v);
- int atomic_dec_and_test(atomic_t *v);
- int atomic_sub_and_test(int i, atomic_t *v);
进行一个特定的操作并且测试结果; 如果, 在操作后, 原子值是 0, 那么返回值是真; 否则, 它是假. 注意没有 atomic_add_and_test.
- int atomic_add_negative(int i, atomic_t *v);
加整数变量 i 到 v. 如果结果是负值返回值是真, 否则为假.
- int atomic_add_return(int i, atomic_t *v);
- int atomic_sub_return(int i, atomic_t *v);
- int atomic_inc_return(atomic_t *v);
- int atomic_dec_return(atomic_t *v);
就像 atomic_add 和其类似函数, 除了它们返回原子变量的新值给调用者.
如同它们说过的, atomic_t 数据项必须通过这些函数存取. 如果你传递一个原子项给一个期望一个整数参数的函数, 你会得到一个编译错误.
你还应当记住, atomic_t 值只在当被置疑的量真正是原子的时候才起作用. 需要多个 atomic_t 变量的操作仍然需要某种其他种类的加锁. 考虑一下下面的代码:
atomic_sub(amount, &first_atomic); atomic_add(amount, &second_atomic);
从第一个原子值中减去 amount, 但是还没有加到第二个时, 存在一段时间. 如果事情的这个状态可能产生麻烦给可能在这 2 个操作之间运行的代码, 某种加锁必须采用.
atomic_t 类型在进行整数算术时是不错的. 但是, 它无法工作的好, 当你需要以原子方式操作单个位时. 为此, 内核提供了一套函数来原子地修改或测试单个位. 因为整个操作在单步内发生, 没有中断(或者其他处理器)能干扰.
原子位操作非常快, 因为它们使用单个机器指令来进行操作, 而在任何时候低层平台做的时候不用禁止中断. 函数是体系依赖的并且在 <asm/bitops.h> 中声明. 它们保证是原子的, 即便在 SMP 计算机上, 并且对于跨处理器保持一致是有用的.
不幸的是, 键入这些函数中的数据也是体系依赖的. nr 参数(描述要操作哪个位)常常定义为 int, 但是在几个体系中是 unsigned long. 要修改的地址常常是一个 unsigned long 指针, 但是几个体系使用 void * 代替.
各种位操作是:
- void set_bit(nr, void *addr);
设置第 nr 位在 addr 指向的数据项中.
- void clear_bit(nr, void *addr);
清除指定位在 addr 处的无符号长型数据. 它的语义与 set_bit 的相反.
- void change_bit(nr, void *addr);
翻转这个位.
- test_bit(nr, void *addr);
这个函数是唯一一个不需要是原子的位操作; 它简单地返回这个位的当前值.
- int test_and_set_bit(nr, void *addr);
- int test_and_clear_bit(nr, void *addr);
- int test_and_change_bit(nr, void *addr);
原子地动作如同前面列出的, 除了它们还返回这个位以前的值.
当这些函数用来存取和修改一个共享的标志, 除了调用它们不用做任何事; 它们以原子发生进行它们的操作. 使用位操作来管理一个控制存取一个共享变量的锁变量, 另一方面, 是有点复杂并且应该有个例子. 大部分现代的代码不以这种方法来使用位操作, 但是象下面的代码仍然在内核中存在.
一段需要存取一个共享数据项的代码试图原子地请求一个锁, 使用 test_and_set_bit 或者 test_and_clear_bit. 通常的实现展示在这里; 它假定锁是在地址 addr 的 nr 位. 它还假定当锁空闲是这个位是 0, 忙为 非零.
/* try to set lock */
while (test_and_set_bit(nr, addr) != 0)
wait_for_a_while();
/* do your work */
/* release lock, and check... */
if (test_and_clear_bit(nr, addr) == 0)
something_went_wrong(); /* already released: error */
如果你通读内核源码, 你会发现象这个例子的代码. 但是, 最好在新代码中使用自旋锁; 自旋锁很好地调试过, 它们处理问题如同中断和内核抢占, 并且别人读你代码时不必努力理解你在做什么.
2.6内核包含了一对新机制打算来提供快速地, 无锁地存取一个共享资源. seqlock 在这种情况下工作, 要保护的资源小, 简单, 并且常常被存取, 并且很少写存取但是必须要快. 基本上, 它们通过允许读者释放对资源的存取, 但是要求这些读者来检查与写者的冲突而工作, 并且当发生这样的冲突时, 重试它们的存取. seqlock 通常不能用在保护包含指针的数据结构, 因为读者可能跟随着一个无效指针而写者在改变数据结构.
seqlock 定义在 <linux/seqlock.h>. 有 2 个通常的方法来初始化一个 seqlock( 有 seqlock_t 类型 ):
seqlock_t lock1 = SEQLOCK_UNLOCKED; seqlock_t lock2; seqlock_init(&lock2);
读存取通过在进入临界区入口获取一个(无符号的)整数序列来工作. 在退出时, 那个序列值与当前值比较; 如果不匹配, 读存取必须重试. 结果是, 读者代码象下面的形式:
unsigned int seq;
do {
seq = read_seqbegin(&the_lock);
/* Do what you need to do */
} while read_seqretry(&the_lock, seq);
这个类型的锁常常用在保护某种简单计算, 需要多个一致的值. 如果这个计算最后的测试表明发生了一个并发的写, 结果被简单地丢弃并且重新计算.
如果你的 seqlock 可能从一个中断处理里存取, 你应当使用 IRQ 安全的版本来代替:
unsigned int read_seqbegin_irqsave(seqlock_t *lock, unsigned long flags); int read_seqretry_irqrestore(seqlock_t *lock, unsigned int seq, unsigned long flags);
写者必须获取一个排他锁来进入由一个 seqlock 保护的临界区. 为此, 调用:
void write_seqlock(seqlock_t *lock);
写锁由一个自旋锁实现, 因此所有的通常的限制都适用. 调用:
void write_sequnlock(seqlock_t *lock);
来释放锁. 因为自旋锁用来控制写存取, 所有通常的变体都可用:
void write_seqlock_irqsave(seqlock_t *lock, unsigned long flags); void write_seqlock_irq(seqlock_t *lock); void write_seqlock_bh(seqlock_t *lock); void write_sequnlock_irqrestore(seqlock_t *lock, unsigned long flags); void write_sequnlock_irq(seqlock_t *lock); void write_sequnlock_bh(seqlock_t *lock);
还有一个 write_tryseqlock 在它能够获得锁时返回非零.
读取-拷贝-更新(RCU) 是一个高级的互斥方法, 能够有高效率在合适的情况下. 它在驱动中的使用很少但是不是没人知道, 因此这里值得快速浏览下. 那些感兴趣 RCU 算法的完整细节的人可以在由它的创建者出版的白皮书中找到( http://www.rdrop.com/users/paulmck/rclock/intro/rclock_intro.html).
RCU 对它所保护的数据结构设置了不少限制. 它对经常读而极少写的情况做了优化. 被保护的资源应当通过指针来存取, 并且所有对这些资源的引用必须由原子代码持有. 当数据结构需要改变, 写线程做一个拷贝, 改变这个拷贝, 接着使相关的指针对准新的版本 -- 因此, 有了算法的名子. 当内核确认没有留下对旧版本的引用, 它可以被释放.
作为在真实世界中使用 RCU 的例子, 考虑一下网络路由表. 每个外出的报文需要请求检查路由表来决定应当使用哪个接口. 这个检查是快速的, 并且, 一旦内核发现了目标接口, 它不再需要路由表入口项. RCU 允许路由查找在没有锁的情况下进行, 具有相当多的性能好处. 内核中的 Startmode 无线 IP 驱动也使用 RCU 来跟踪它的设备列表.
使用 RCU 的代码应当包含 <linux/rcupdate.h>.
在读这一边, 使用一个 RCU-保护的数据结构的代码应当用 rcu_read_lock 和 rcu_read_unlock 调用将它的引用包含起来. 结果就是, RCU 代码往往是象这样:
struct my_stuff *stuff; rcu_read_lock(); stuff = find_the_stuff(args...); do_something_with(stuff); rcu_read_unlock();
rcu_read_lock 调用是快的; 它禁止内核抢占但是没有等待任何东西. 在读"锁"被持有时执行的代码必须是原子的. 在对 rcu_read_unlock 调用后, 没有使用对被保护的资源的引用.
需要改变被保护的结构的代码必须进行几个步骤. 第一步是容易的; 它分配一个新结构, 如果需要就从旧的拷贝数据, 接着替换读代码所看到的指针. 在此, 对于读一边的目的, 改变结束了. 任何进入临界区的代码看到数据的新版本.
剩下的是释放旧版本. 当然, 问题是在其他处理器上运行的代码可能仍然有对旧数据的一个引用, 因此它不能立刻释放. 相反, 写代码必须等待直到它知道没有这样的引用存在了. 因为所有持有对这个数据结构引用的代码必须(规则规定)是原子的, 我们知道一旦系统中的每个处理器已经被调度了至少一次, 所有的引用必须消失. 这就是 RCU 所做的; 它留下了一个等待直到所有处理器已经调度的回调; 那个回调接下来被运行来进行清理工作.
改变一个 RCU-保护的数据结构的代码必须通过分配一个 struct rcu_head 来获得它的清理回调, 尽管不需要以任何方式初始化这个结构. 常常, 那个结构被简单地嵌入在 RCU 所保护的大的资源里面. 在改变资源完成后, 应当调用:
void call_rcu(struct rcu_head *head, void (*func)(void *arg), void *arg);
给定的 func 在释放资源是安全的时候调用; 传递给 call_rcu的是给同一个 arg. 常常, func 需要的唯一的东西是调用 kfree.
全部 RCU 接口比我们已见的要更加复杂; 它包括, 例如, 辅助函数来使用被保护的链表. 全部内容见相关的头文件.