不是描述操作系统的内存管理理论, 本节试图指出 Linux 实现的主要特点. 尽管你不必是一位 Linux 虚拟内存专家来实现 mmap, 一个对事情如何工作的基本了解是有用的. 下面是一个相当长的对内核使用来管理内存的数据结构的描述. 一旦必要的背景已被覆盖, 我们就进入使用这个结构.
Linux 是, 当然, 一个虚拟内存系统, 意味着用户程序见到的地址不直接对应于硬件使用的物理地址. 虚拟内存引入了一个间接层, 它允许了许多好事情. 有了虚拟内存, 系统重运行的程序可以分配远多于物理上可用的内存; 确实, 即便一个单个进程可拥有一个虚拟地址空间大于系统的物理内存. 虚拟内存也允许程序对进程的地址空间运用多种技巧, 包括映射成员的内存到设备内存.
至此, 我们已经讨论了虚拟和物理地址, 但是许多细节被掩盖过去了. Linux 系统处理几种类型的地址, 每个有它自己的含义. 不幸的是, 内核代码不是一直非常清楚确切地在每个情况下在使用什么类型地地址, 因此程序员必须小心.
下面是一个 Linux 中使用的地址类型列表. 图 Linux 中使用的地址类型显示了这个地址类型如何关联到物理内存.
- User virtual addresses
-
这是被用户程序见到的常规地址. 用户地址在长度上是 32 位或者 64 位, 依赖底层的硬件结构, 并且每个进程有它自己的虚拟地址空间.
- Physical addresses
-
在处理器和系统内存之间使用的地址. 物理地址是 32- 或者 64-位的量; 甚至 32-位系统在某些情况下可使用更大的物理地址.
- Bus addresses
-
在外设和内存之间使用的地址. 经常, 它们和被处理器使用的物理地址相同, 但是这不是必要的情况. 一些体系可提供一个 I/O 内存管理单元(IOMMU), 它在总线和主内存之间重映射地址. 一个 IOMMU 可用多种方法使事情简单(例如, 使散布在内存中的缓冲对设备看来是连续的, 例如), 但是当设定 DMA 操作时对 IOMMU 编程是一个必须做的额外的步骤. 总线地址是高度特性依赖的, 当然.
- Kernel logical addresses
-
这些组成了正常的内核地址空间. 这些地址映射了部分(也许全部)主存并且常常被当作它们是物理内存来对待. 在大部分的体系上, 逻辑地址和它们的相关物理地址只差一个常量偏移. 逻辑地址使用硬件的本地指针大小并且, 因此, 可能不能在重装备的 32-位系统上寻址所有的物理内存. 逻辑地址常常存储于 unsigned long 或者 void * 类型的变量中. 从 kmalloc 返回的内存有内核逻辑地址.
- Kernel virtual addresses
-
内核虚拟地址类似于逻辑地址, 它们都是从内核空间地址到物理地址的映射. 内核虚拟地址不必有逻辑地址空间具备的线性的, 一对一到物理地址的映射, 但是. 所有的逻辑地址是内核虚拟地址, 但是许多内核虚拟地址不是逻辑地址. 例如, vmalloc 分配的内存有虚拟地址(但没有直接物理映射). kmap 函数(本章稍后描述)也返回虚拟地址. 虚拟地址常常存储于指针变量.
如果你有逻辑地址, 宏 __pa() ( 在 <asm/page.h> 中定义)返回它的关联的物理地址. 物理地址可被映射回逻辑地址使用 __va(), 但是只给低内存页.
不同的内核函数需要不同类型地址. 如果有不同的 C 类型被定义可能不错, 这样请求的地址类型是明确的, 但是我们没有这样的好运. 在本章, 我们尽力对在哪里使用哪种类型地址保持清晰.
物理内存被划分为离散的单元称为页. 系统的许多内部内存处理在按页的基础上完成. 页大小一个体系不同于另一个, 尽管大部分系统当前使用 4096-字节的页. 常量 PAGE_SIZE (定义在 <asm/page.h>) 给出了页大小在任何给定的体系上.
如果你查看一个内存地址 - 虚拟或物理 - 它可分为一个页号和一个页内的偏移. 如果使用 4096-字节页, 例如, 12 位低有效位是偏移, 并且剩下的, 高位指示页号. 如果你丢弃偏移并且向右移动剩下的部分 offset 位, 结果被称为一个页帧号 (PFN). 移位来在页帧号和地址之间转换是一个相当普通的操作. 宏 PAGE_SHIFT 告诉必须移动多少位来进行这个转换.
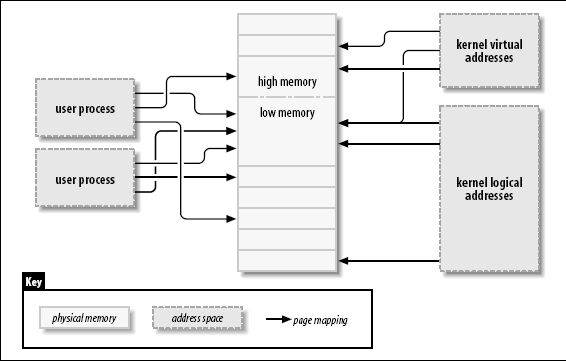
逻辑和内核虚拟地址之间的不同在配备大量内存的 32-位系统中被突出. 用 32 位, 可能寻址 4 G 内存. 但是, 直到最近, 在 32-位 系统的 Linux 被限制比那个少很多的内存, 因为它建立虚拟地址的方式.
内核( 在 x86 体系上, 在缺省配置里) 在用户空间和内核之间划分 4-G 虚拟地址; 在 2 个上下文中使用同一套映射. 一个典型的划分分出 3 GB 给用户空间, 和 1 GB 给内核空间. [47]内核的代码和数据结构必须要适合这个空间, 但是内核地址空间最大的消费者是物理内存的虚拟映射. 内核不能直接操作没有映射到内核的地址空间. 内核, 换句话说, 需要它自己的虚拟地址给任何它必须直接接触的内存. 因此, 多年来, 能够被内核处理的的最大量的物理内存是能够映射到虚拟地址的内核部分的数量, 减去内核代码自身需要的空间. 结果, 基于 x86 的 Linux 系统可以工作在最多稍小于 1 GB 物理内存.
为应对更多内存的商业压力而不破坏 32-位 应用和系统的兼容性, 处理器制造商已经增加了"地址扩展"特性到他们的产品中. 结果, 在许多情况下, 即便 32-位 处理器也能够寻址多于 4GB 物理内存. 但是, 多少内存可被直接用逻辑地址映射的限制还存在. 这样内存的最低部分(上到 1 或 2 GB, 根据硬件和内核配置)有逻辑地址; 剩下的(高内存)没有. 在存取一个特定高地址页之前, 内核必须建立一个明确的虚拟映射来使这个也在内核地址空间可用. 因此, 许多内核数据结构必须放在低内存; 高内存用作被保留为用户进程页.
术语"高内存"对有些人可能是疑惑的, 特别因为它在 PC 世界里有其他的含义. 因此, 为清晰起见, 我们将定义这些术语:
- Low memory
-
逻辑地址在内核空间中存在的内存. 在大部分每个系统你可能会遇到, 所有的内存都是低内存.
- High memory
-
逻辑地址不存在的内存, 因为它在为内核虚拟地址设置的地址范围之外.
在 i386 系统上, 低和高内存之间的分界常常设置在刚刚在 1 GB 之下, 尽管那个边界在内核配置时可被改变. 这个边界和在原始 PC 中有的老的 640 KB 限制没有任何关联, 并且它的位置不是硬件规定的. 相反, 它是, 内核自身设置的一个限制当它在内核和用户空间之间划分 32-位地址空间时.
我们将指出使用高内存的限制, 随着我们在本章遇到它们时.
历史上, 内核已使用逻辑地址来引用物理内存页. 高内存支持的增加, 但是, 已暴露这个方法的一个明显的问题 -- 逻辑地址对高内存不可用. 因此, 处理内存的内核函数更多在使用指向 struct page 的指针来代替(在 <linux/mm.h> 中定义). 这个数据结构只是用来跟踪内核需要知道的关于物理内存的所有事情.
2.6 内核(带一个增加的补丁)可以支持一个 "4G/4G" 模式在 x86 硬件上, 它以微弱的性能代价换来更大的内核和用户虚拟地址空间.
系统中每一个物理页有一个 struct page. 这个结构的一些成员包括下列:
- atomic_t count;
-
这个页的引用数. 当这个 count 掉到 0, 这页被返回给空闲列表.
- void *virtual;
-
这页的内核虚拟地址, 如果它被映射; 否则, NULL. 低内存页一直被映射; 高内存页常常不是. 这个成员不是在所有体系上出现; 它通常只在页的内核虚拟地址无法轻易计算时被编译. 如果你想查看这个成员, 正确的方法是使用 page_address 宏, 下面描述.
- unsigned long flags;
-
一套描述页状态的一套位标志. 这些包括 PG_locked, 它指示该页在内存中已被加锁, 以及 PG_reserved, 它防止内存管理系统使用该页.
有很多的信息在 struct page 中, 但是它是内存管理的更深的黑魔法的一部分并且和驱动编写者无关.
内核维护一个或多个 struct page 项的数组来跟踪系统中所有物理内存. 在某些系统, 有一个单个数组称为 mem_map. 但是, 在某些系统, 情况更加复杂. 非一致内存存取( NUMA )系统和那些有很大不连续的物理内存的可能有多于一个内存映射数组, 因此打算是可移植的代码在任何可能时候应当避免直接对数组存取. 幸运的是, 只是使用 struct page 指针常常是非常容易, 而不用担心它们来自哪里.
有些函数和宏被定义来在 struct page 指针和虚拟地址之间转换:
- struct page *virt_to_page(void *kaddr);
-
这个宏, 定义在 <asm/page.h>, 采用一个内核逻辑地址并返回它的被关联的 struct page 指针. 因为它需要一个逻辑地址, 它不使用来自 vmalloc 的内存或者高内存.
- struct page *pfn_to_page(int pfn);
-
为给定的页帧号返回 struct page 指针. 如果需要, 它在传递给 pfn_to_page 之前使用 pfn_valid 来检查一个页帧号的有效性.
- void *page_address(struct page *page);
-
返回这个页的内核虚拟地址, 如果这样一个地址存在. 对于高内存, 那个地址仅当这个页已被映射才存在. 这个函数在 <linux/mm.h> 中定义. 大部分情况下, 你想使用 kmap 的一个版本而不是 page_address.
- #include <linux/highmem.h>
- void *kmap(struct page *page);
- void kunmap(struct page *page);
-
kmap 为系统中的任何页返回一个内核虚拟地址. 对于低内存页, 它只返回页的逻辑地址; 对于高内存, kmap 在内核地址空间的一个专用部分中创建一个特殊的映射. 使用 kmap 创建的映射应当一直使用 kunmap 来释放;一个有限数目的这样的映射可用, 因此最好不要在它们上停留太长时间. kmap 调用维护一个计数器, 因此如果 2 个或 多个函数都在同一个页上调用 kmap, 正确的事情发生了. 还要注意 kmap 可能睡眠当没有映射可用时.
- #include <linux/highmem.h>
- #include <asm/kmap_types.h>
- void *kmap_atomic(struct page *page, enum km_type type);
- void kunmap_atomic(void *addr, enum km_type type);
-
kmap_atomic 是 kmap 的一种高性能形式. 每个体系都给原子的 kmaps 维护一小列插口( 专用的页表项); 一个 kmap_atomic 的调用者必须在 type 参数中告知系统使用这些插口中的哪个. 对驱动有意义的唯一插口是 KM_USER0 和 KM_USER1 (对于直接从来自用户空间的调用运行的代码), 以及 KM_IRQ0 和 KM_IRQ1(对于中断处理). 注意原子的 kmaps 必须被原子地处理; 你的代码不能在持有一个时睡眠. 还要注意内核中没有什么可以阻止 2 个函数试图使用同一个插口并且相互干扰( 尽管每个 CPU 有独特的一套插口). 实际上, 对原子的 kmap 插口的竞争看来不是个问题.
在本章后面和后续章节中当我们进入例子代码时, 我们看到这些函数的一些使用,
在任何现代系统上, 处理器必须有一个机制来转换虚拟地址到它的对应物理地址. 这个机制被称为一个页表; 它本质上是一个多级树型结构数组, 包含了虚拟-到-物理的映射和几个关联的标志. Linux 内核维护一套页表即便在没有直接使用这样页表的体系上.
设备驱动通常可以做的许多操作能涉及操作页表. 幸运的是对于驱动作者, 2.6 内核已经去掉了任何直接使用页表的需要. 结果是, 我们不描述它们的任何细节; 好奇的读者可能想读一下 Understanding The Linux Kernel 来了解完整的内容, 作者是 Daniel P. Bovet 和 Marco Cesati (O' Reilly).
虚拟内存区( VMA )用来管理一个进程的地址空间的独特区域的内核数据结构. 一个 VMA 代表一个进程的虚拟内存的一个同质区域: 一个有相同许可标志和被相同对象(如, 一个文件或者交换空间)支持的连续虚拟地址范围. 它松散地对应于一个"段"的概念, 尽管可以更好地描述为"一个有它自己特性的内存对象". 一个进程的内存映射有下列区组成:
-
给程序的可执行代码(常常称为 text)的一个区.
-
给数据的多个区, 包括初始化的数据(它有一个明确的被分配的值, 在执行开始), 未初始化数据(BBS), [48]以及程序堆栈.
-
给每个激活的内存映射的一个区域.
一个进程的内存区可看到通过 /proc/<pid/maps>(这里 pid, 当然, 用一个进程的 ID 来替换). /proc/self 是一个 /proc/id 的特殊情况, 因为它常常指当前进程. 作为一个例子, 这里是几个内存映射(我们添加了简短注释)
# cat /proc/1/maps look at init 08048000-0804e000 r-xp 00000000 03:01 64652 0804e000-0804f000 rw-p 00006000 03:01 64652 0804f000-08053000 rwxp 00000000 00:00 0 40000000-40015000 r-xp 00000000 03:01 96278 40015000-40016000 rw-p 00014000 03:01 96278 40016000-40017000 rw-p 00000000 00:00 0 42000000-4212e000 r-xp 00000000 03:01 80290 4212e000-42131000 rw-p 0012e000 03:01 80290 42131000-42133000 rw-p 00000000 00:00 0 bffff000-c0000000 rwxp 00000000 00:00 0 ffffe000-fffff000 ---p 00000000 00:00 0 /sbin/init text /sbin/init data zero-mapped BSS /lib/ld-2.3.2.so text /lib/ld-2.3.2.so data BSS for ld.so /lib/tls/libc-2.3.2.so text /lib/tls/libc-2.3.2.so data BSS for libc Stack segment vsyscall page # rsh wolf cat /proc/self/maps #### x86-64 (trimmed) 00400000-00405000 r-xp 00000000 03:01 1596291 /bin/cat text 00504000-00505000 rw-p 00004000 03:01 1596291 /bin/cat data 00505000-00526000 rwxp 00505000 00:00 0 bss 3252200000-3252214000 r-xp 00000000 03:01 1237890 /lib64/ld-2.3.3.so 3252300000-3252301000 r--p 00100000 03:01 1237890 /lib64/ld-2.3.3.so 3252301000-3252302000 rw-p 00101000 03:01 1237890 /lib64/ld-2.3.3.so 7fbfffe000-7fc0000000 rw-p 7fbfffe000 00:00 0 stack ffffffffff600000-ffffffffffe00000 ---p 00000000 00:00 0 vsyscall
每行的字段是:
start-end perm offset major:minor inode image
每个在 /proc/*/maps (出来映象的名子) 对应 struct vm_area_struct 中的一个成员:
- start end
-
这个内存区的开始和结束虚拟地址.
- perm
-
带有内存区的读,写和执行许可的位掩码. 这个成员描述进程可以对属于这个区的页做什么. 成员的最后一个字符要么是给"私有"的 p 要么是给"共享"的 s.
- offset
-
内存区在它被映射到的文件中的起始位置. 0 偏移意味着内存区开始对应文件的开始.
- major minor
-
持有已被映射文件的设备的主次编号. 易混淆地, 对于设备映射, 主次编号指的是持有被用户打开的设备特殊文件的磁盘分区, 不是设备自身.
- inode
-
被映射文件的 inode 号.
- image
-
已被映射的文件名((常常在一个可执行映象中).
当一个用户空间进程调用 mmap 来映射设备内存到它的地址空间, 系统通过一个新 VMA 代表那个映射来响应. 一个支持 mmap 的驱动(并且, 因此, 实现 mmap 方法)需要来帮助那个进程来完成那个 VMA 的初始化. 驱动编写者应当, 因此, 为支持 mmap 应至少有对 VMA 的最少的理解.
让我们看再 struct vm_area_struct 中最重要的成员( 在 <linux/mm.h> 中定义). 这些成员应当被设备驱动在它们的 mmap 实现中使用. 注意内核维护 VMA 的链表和树来优化区查找, 并且 vm_area_struct 的几个成员被用来维护这个组织. 因此, VMA 不是有一个驱动任意创建的, 否则这个结构破坏了. VMA 的主要成员是下面(注意在这些成员和我们刚看到的 /proc 输出之间的相似)
- unsigned long vm_start;
- unsigned long vm_end;
-
被这个 VMA 覆盖的虚拟地址范围. 这些成员是在 /proc/*/maps中出现的头 2 个字段.
- struct file *vm_file;
-
一个指向和这个区(如果有一个)关联的 struct file 结构的指针.
- unsigned long vm_pgoff;
-
文件中区的偏移, 以页计. 当一个文件和设备被映射, 这是映射在这个区的第一页的文件位置.
- unsigned long vm_flags;
-
描述这个区的一套标志. 对设备驱动编写者最感兴趣的标志是 VM_IO 和 VM_RESERVUED. VM_IO 标志一个 VMA 作为内存映射的 I/O 区. 在其他方面, VM_IO 标志阻止这个区被包含在进程核转储中. VM_RESERVED 告知内存管理系统不要试图交换出这个 VMA; 它应当在大部分设备映射中设置.
- struct vm_operations_struct *vm_ops;
-
一套函数, 内核可能会调用来在这个内存区上操作. 它的存在指示内存区是一个内核"对象", 象我们已经在全书中使用的 struct file.
- void *vm_private_data;
-
驱动可以用来存储它的自身信息的成员.
象 struct vm_area_struct, vm_operations_struct 定义于 <linux/mm.h>; 它包括下面列出的操作. 这些操作是唯一需要来处理进程的内存需要的, 它们以被声明的顺序列出. 本章后面, 一些这些函数被实现.
- void (*open)(struct vm_area_struct *vma);
-
open 方法被内核调用来允许实现 VMA 的子系统来初始化这个区. 这个方法被调用在任何时候有一个新的引用这个 VMA( 当生成一个新进程, 例如). 一个例外是当这个 VMA 第一次被 mmap 创建时; 在这个情况下, 驱动的 mmap 方法被调用来替代.
- void (*close)(struct vm_area_struct *vma);
-
当一个区被销毁, 内核调用它的关闭操作. 注意没有使用计数关联到 VMA; 这个区只被使用它的每个进程打开和关闭一次.
- struct page *(*nopage)(struct vm_area_struct *vma, unsigned long address, int *type);
-
当一个进程试图存取使用一个有效 VMA 的页, 但是它当前不在内存中, nopage 方法被调用(如果它被定义)给相关的区. 这个方法返回 struct page 指针给物理页, 也许在从第 2 级存储中读取它之后. 如果 nopage 方法没有为这个区定义, 一个空页由内核分配.
- int (*populate)(struct vm_area_struct *vm, unsigned long address, unsigned long len, pgprot_t prot, unsigned long pgoff, int nonblock);
-
这个方法允许内核"预错"页到内存, 在它们被用户空间存取之前. 对于驱动通常没有必要来实现这个填充方法.
内存管理难题的最后部分是进程内存映射结构, 它保持所有其他数据结构在一起. 每个系统中的进程(除了几个内核空间帮助线程)有一个 struct mm_struct ( 定义在 <linux/sched.h>), 它含有进程的虚拟内存区列表, 页表, 和各种其他的内存管理管理信息, 包括一个旗标( mmap_sem )和一个自旋锁( page_table_lock ). 这个结构的指针在任务结构中; 在很少的驱动需要存取它的情况下, 通常的方法是使用 current->mm. 注意内存关联结构可在进程之间共享; Linux 线程的实现以这种方式工作, 例如.
这总结了我们对 Linux 内存管理数据结构的总体. 有了这些, 我们现在可以继续 mmap 系统调用的实现.
[47] 许多非-x86体系可以有效工作在没有这里描述的内核/用户空间的划分, 因此它们可以在 32-位系统使用直到 4-GB 内核地址空间. 但是, 本节描述的限制仍然适用这样的系统当安装有多于 4GB 内存时.
[48] BSS 的名子是来自一个老的汇编操作符的历史遗物, 意思是"由符号开始的块". 可执行文件的 BSS 段不存储在磁盘上, 并且内核映射零页到 BSS 地址范围.